Видео с ютуба Metal Inference Engine

Building an LLM Inference Engine on Apple Silicon - Part 1: How GPT Actually Works

Nvidia CUDA vs Apple Metal for AI Work

DwarfStar -- DeepSeek 4 Flash local inference engine for Metal and CUDA

Освоение vLLM на практическом примере
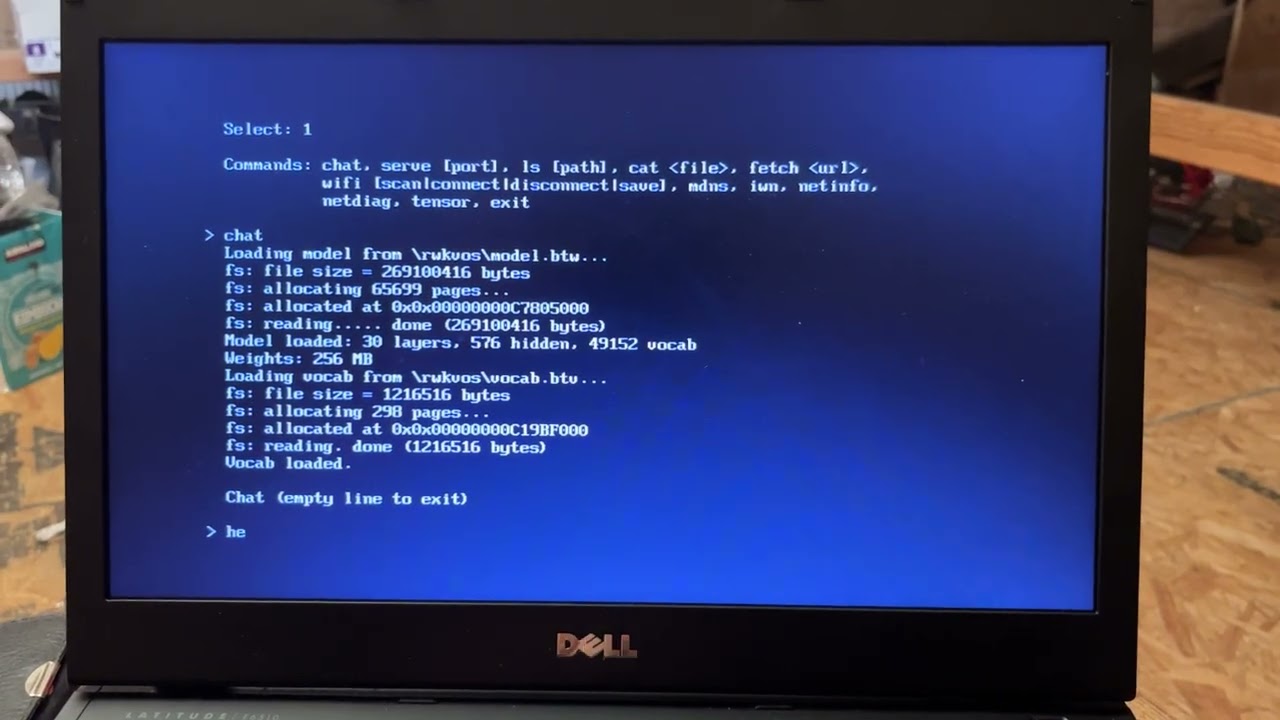
Bare-Metal AI: Booting Directly Into LLM Inference ‚ No OS, No Kernel (Dell E6510)

ds4: antirez's New Inference Engine — 7.1k Stars in 4 Days

This Changes AI Serving Forever | vLLM-Omni Walkthrough

Your local LLM is 10x slower than it should be

Docker Model Runner: vLLM Support for Apple Silicon Metal

antirez 'chơi lớn' với AI local: Đám mây sắp vô dụng?

Faster LLMs: Accelerate Inference with Speculative Decoding
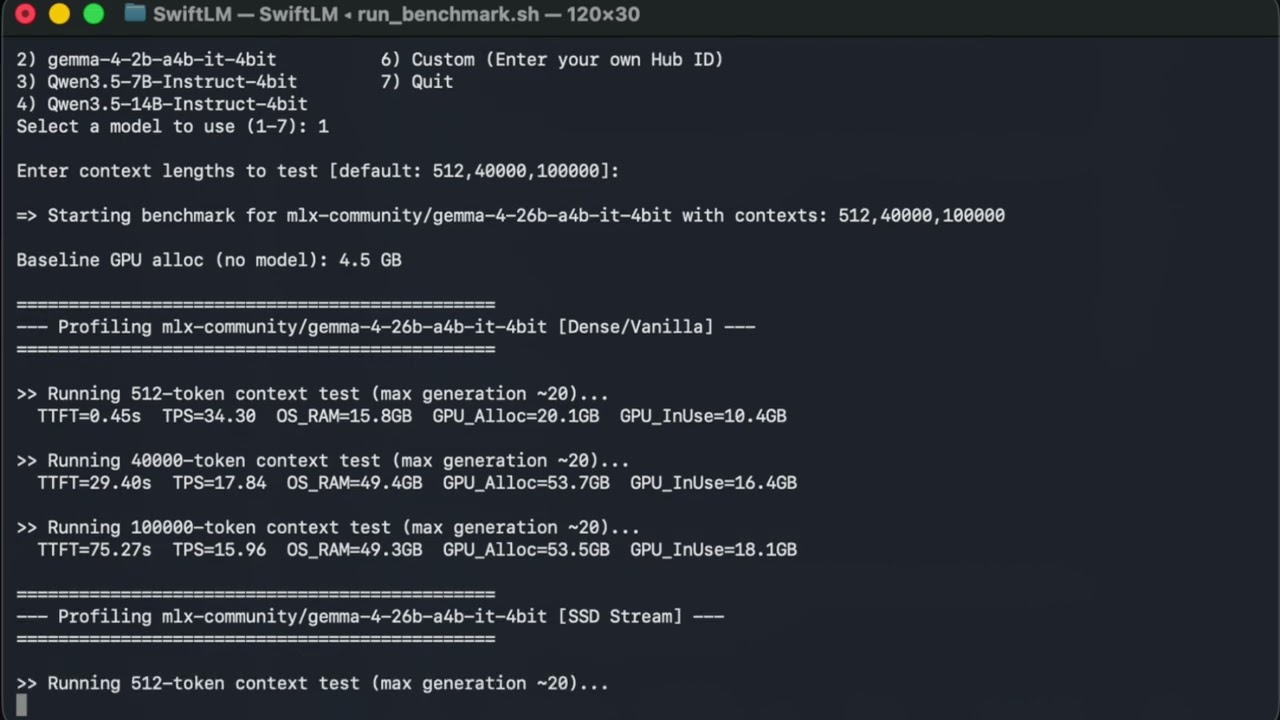
How to Inference Gemma 4 Locally on Mac (M1 8GB to M5 MAX) with SwiftLM

Silicate Zero: Booting an AI on Bare Metal
WWDC21: Accelerate machine learning with Metal Performance Shaders Graph | Apple

Nvidia CUDA in 100 Seconds

HC32-S8: ML Inference

Utah Colo - Ai Bare Metal to Agent Loops w/ Christopher Brousseau

THIS is the REAL DEAL 🤯 for local LLMs

Inference Engine - Live 2016 (full album)

Анонсируем общедоступные процессоры Ironwood TPU и новые виртуальные машины Axion для поддержки э...